| 文件名 | dataprocess_invalid.xlsx |
|---|---|
| 数据用途 | 无效样本案例数据 |
| 变量说明 | Q1 到 Q8 为量表题,duration_sec 为答题时长,attention_check 为注意力检验题。 |
完整案例
1. 背景
问卷回收后,部分样本存在全选同一分值、缺失比例过高或答题时长异常短的问题,需要先标记再筛选。
2. 理论与公式
无效样本识别通常基于缺失比例、同值比例、注意力题或答题时长等质量规则。
缺失比例
第 i 个样本缺失题项数占总题项数的比例。
同值比例
某个样本中出现最多的同一分值占比。
有效标识
满足质量规则的样本标记为有效。
3. 数据结构
Q1 到 Q8 为量表题,duration_sec 为答题时长,attention_check 为注意力检验题。
4. 操作步骤与截图
- 上传案例数据
- 进入无效样本
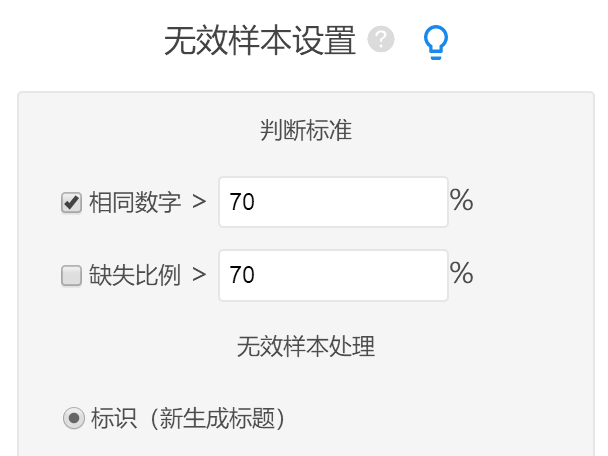
- 选中需要判断的量表题
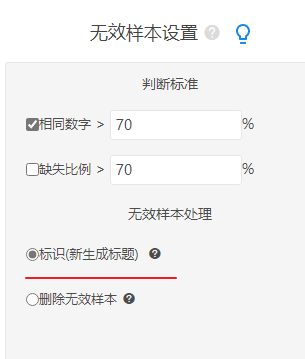
- 设置相同数字比例或缺失比例阈值
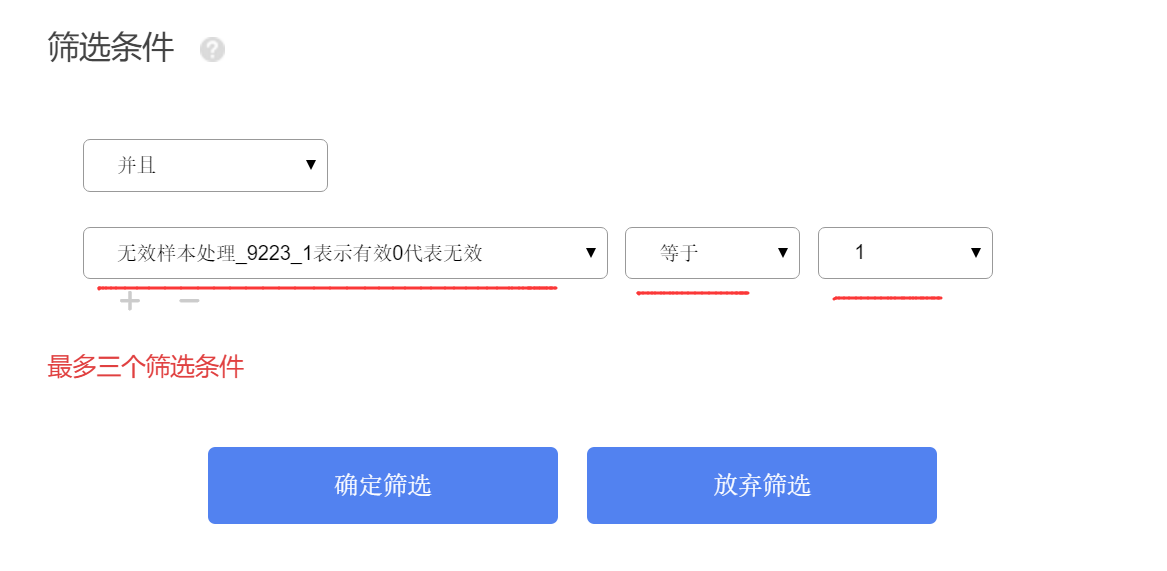
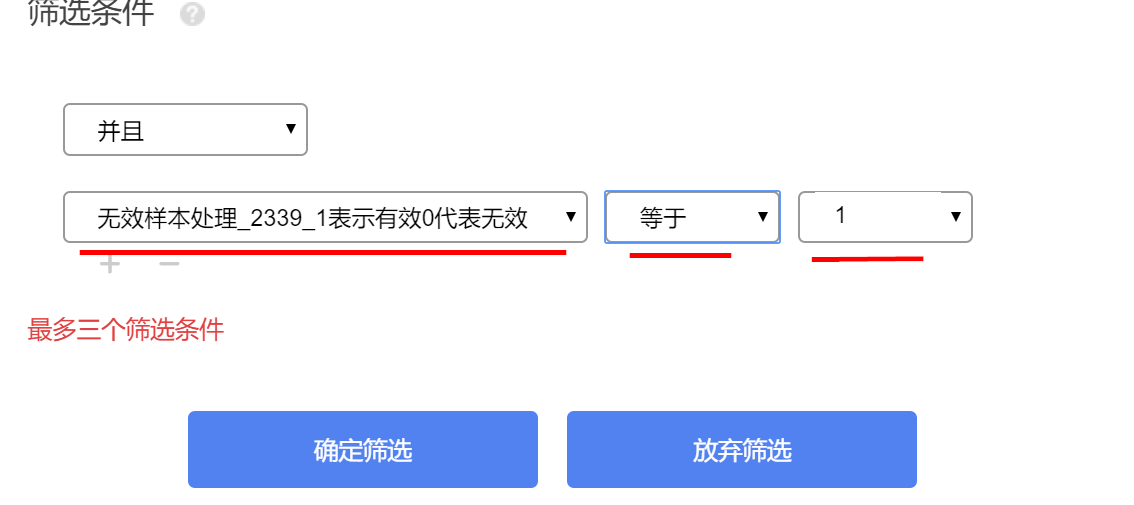
- 生成有效样本标识并使用筛选样本分析
5. 结果表格与核验
| 样本 | 同值比例 | 缺失比例 | 答题时长 | 有效标识 |
|---|---|---|---|---|
| S001 | 25.0% | 0.0% | 186 秒 | 1 |
| S006 | 100.0% | 0.0% | 38 秒 | 0 |
| S010 | 37.5% | 75.0% | 142 秒 | 0 |
有效标识为 1 的样本进入后续分析,0 可通过筛选样本排除。
重点查看有效样本标识的 0/1 分布,确认被标记样本是否符合预设规则。
6. 辅助截图

7. 文字分析
无效样本识别后,后续分析应基于有效样本进行,以降低乱填、漏填或异常作答对统计结论的干扰。
8. 剖析提醒
无效样本标准需要事先说明,不建议分析后为了改变结果随意调整阈值。